









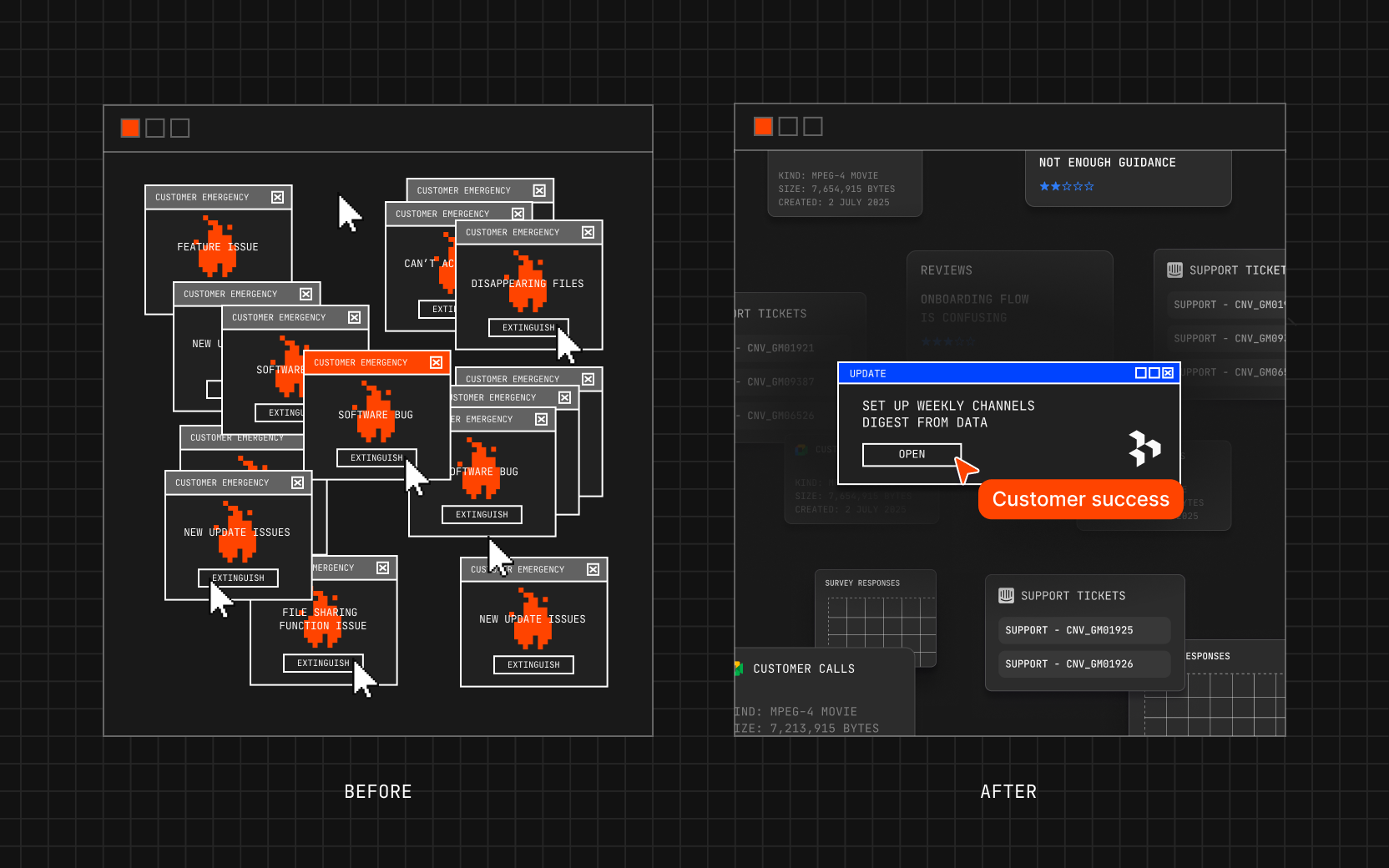

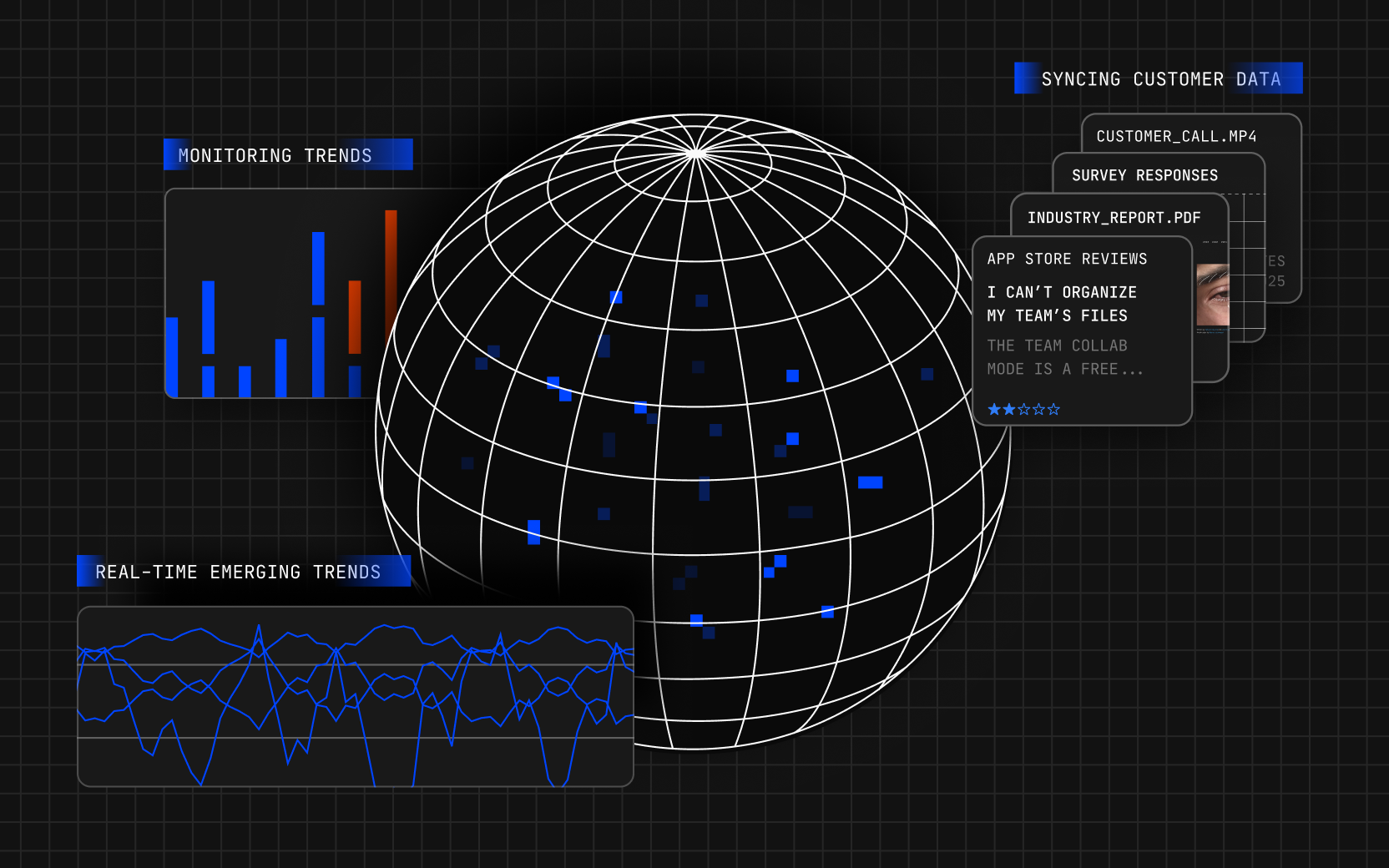








































Outlier is for the rebels, trailblazers, and pioneers. Always ahead of the pack, Outlier celebrates the exceptional—the organizations, products, and people that break the bellcurve and change the world.
Outlier is for the rebels, trailblazers, and pioneers. Always ahead of the pack, Outlier celebrates the exceptional—the organizations, products, and people that break the bellcurve and change the world.