How we measure AI quality at Dovetail
At Dovetail, we believe AI quality should be measurable, transparent, and continuously improving. Rather than relying on vague claims about accuracy or intelligence, we evaluate AI systems using clear metrics tied to real user outcomes.
As AI becomes embedded in everyday product workflows, one question comes up repeatedly from customers: How do you know the AI is actually reliable?
At Dovetail, we believe AI quality should be measurable, transparent, and continuously improving. Rather than relying on vague claims about accuracy or intelligence, we evaluate AI systems using clear metrics tied to real user outcomes.
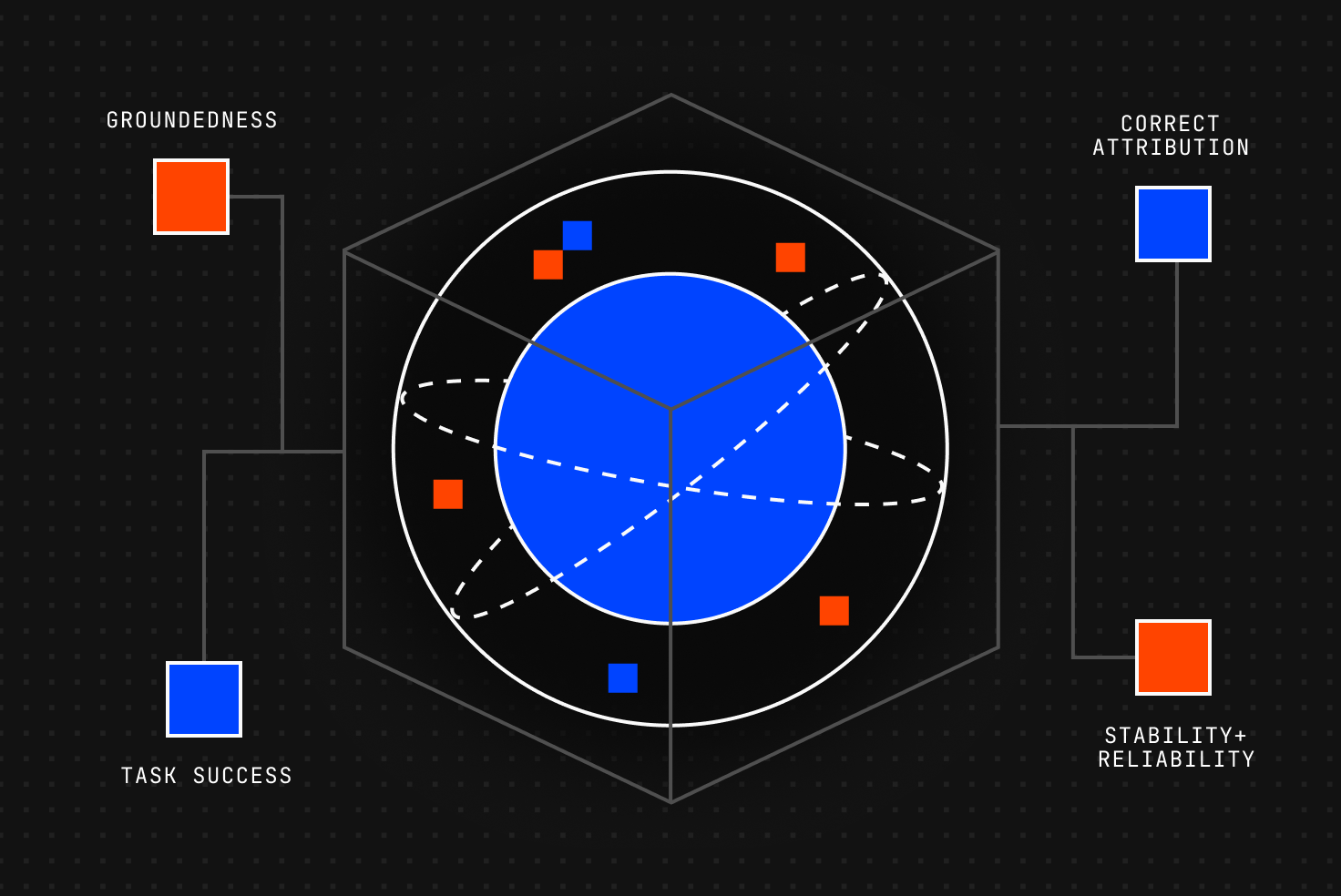
This article outlines the framework we use to evaluate AI quality across four pillars: groundedness, task success, correct attribution, and reliability. These pillars reflect both established AI evaluation research and the practical concerns customers raise when trusting AI to analyze and synthesize customer data.
For Dovetail, an AI quality framework needs to do more than guide internal evaluation. It also needs to help customer-facing teams answer questions about how our AI performs in practice.
Our AI quality framework serves two purposes
It helps equip customer-facing teams with clear, defensible answers when AI quality is questioned, while creating internal accountability for meeting measurable performance standards.
AI systems are probabilistic by nature. The goal is not perfection. It is measurable, controlled, and continuously improving performance.
Our framework measures AI quality across four pillars aligned with industry evaluation standards used by OpenAI, Anthropic, Stanford HELM, and established information retrieval research.
What customers expect from AI quality
Our users expect measurable reliability. The metrics we track reflect the qualities customers consistently ask about: accuracy, traceability, usefulness, and consistency.
From there, our framework breaks AI quality into four measurable pillars:
1. Groundedness
AI responses must be supported by source data (not inferences presented as facts)
We measure:
- Unsupported claim rate (hallucination rate)
- Citation coverage
- Evidence traceability
Targets:
- Fewer than 10% unsupported claims
- More than 90% of claims are backed by citations
These standards align with established evaluation frameworks such as TruthfulQA, Stanford HELM, and retrieval faithfulness metrics used in RAG evaluations.
2. Task success
AI should help the user complete the task, not just produce plausible text.
We measure:
- Full task completion rate
- Partial vs incorrect responses
Targets:
- More than 95% full task success on core workflows
- More than 80% relevance in top results
This reflects how leading AI systems are evaluated through benchmark tasks, human preference scoring, and structured eval frameworks (such as MMLU and OpenAI’s frameworks)
3. Correct attribution
When AI analyzes customer conversations, correct interpretation depends on correct perspective.
We measure:
- Speaker attribution accuracy
- Sentiment classification accuracy
Targets:
- More than 90% speaker attribution accuracy
- More than 90% sentiment accuracy
These metrics follow standard supervised machine learning evaluation methods, including accuracy, precision, and recall.
4. Stability and reliability
AI quality also depends on consistency and system performance over time.
We measure:
- Major output variance
- Timeout and failure rate
- Latency thresholds
Targets:
- Fewer than 10% major output variance
- Fewer than 2% system error rate
These measures reflect established enterprise SaaS reliability practices and model robustness standards.
These metrics aren’t arbitrary
They are grounded in established evaluation approaches used across modern AI systems and information retrieval research, including:
- OpenAI system card evaluation categories
- Anthropic research on factual consistency and safety
- Stanford HELM benchmarking
- Retrieval faithfulness metrics such as RAGAS
- Classical information retrieval standards such as Precision@k and NDCG
- Standard machine learning evaluation methods, including accuracy, F1, and precision/recall
These are the same categories used to evaluate modern AI systems in both academic research and production environments.
High-quality AI requires continuous improvement
We continuously evaluate model performance and adopt model upgrades when they demonstrate measurable improvements in groundedness, task success, or reliability. Model selection is benchmark-driven and task-specific.
Alongside structured quality benchmarks, we also incorporate direct user feedback, such as thumbs-up and thumbs-down ratings on AI responses.
User feedback does not replace formal evaluation metrics, but it does provide a continuous real-world validation loop that helps ensure measured quality aligns with the in-product experience.
Related Articles